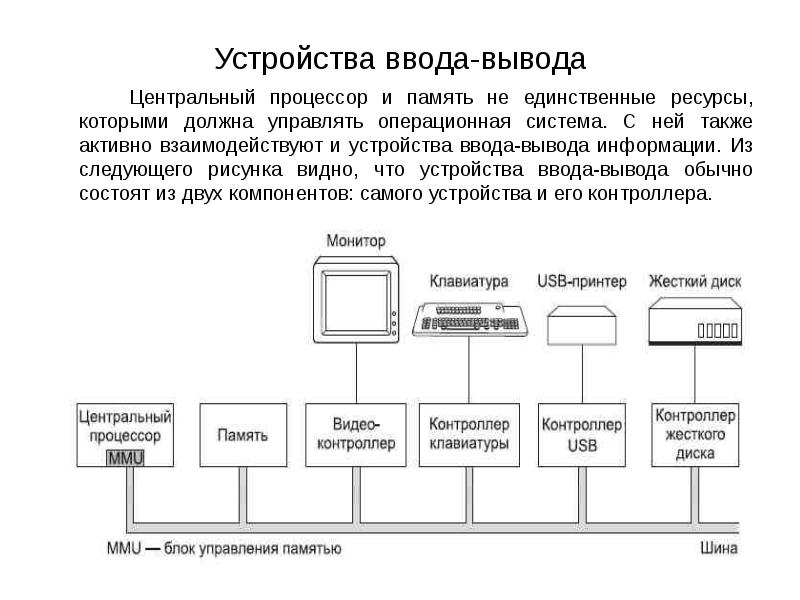
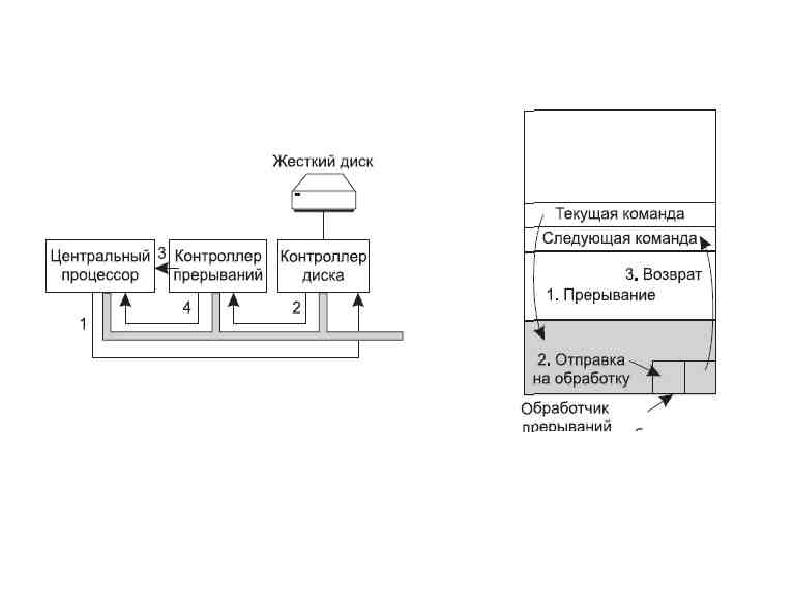
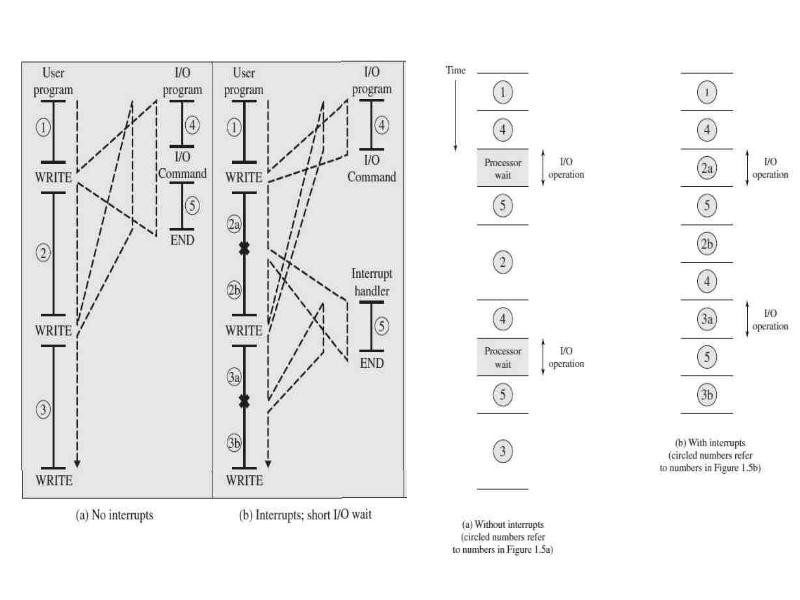
Описание слайда:
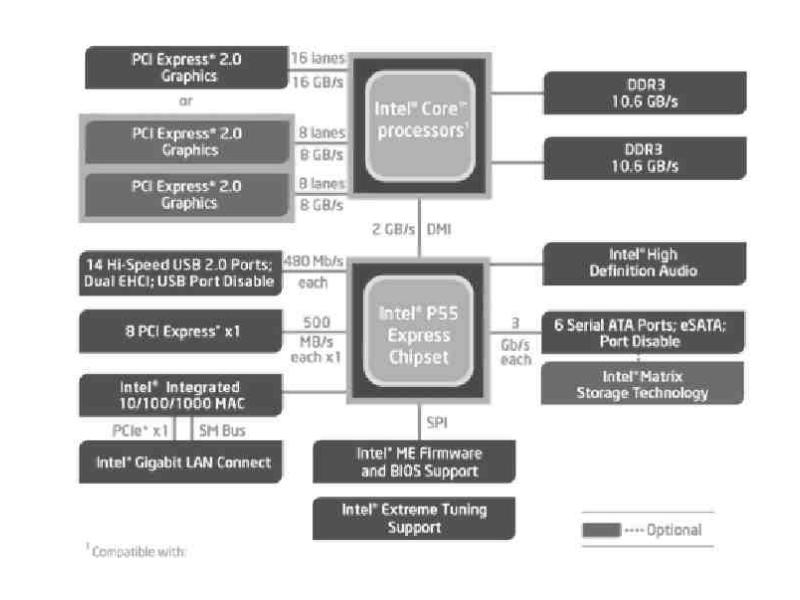
Архитектура параллельной шины, подобная той, что используется в PCI, предполагает отправку каждого слова данных по нескольким проводникам. Например, в обычных шинах PCI одно 32-разрядное число отправляется по 32 параллельным проводникам. В отличие от этого в PCIe используется архитектура последовательной шины, и все биты сообщения отправляются по одному соединению, известному как дорожка (lane), что очень похоже на отправку сетевого пакета. Это существенно упрощает задачу, поскольку обеспечивать абсолютно одновременное прибытие всех 32 битов в пункт назначения уже не нужно. Но параллелизм все же используется, поскольку параллельно могут действовать сразу несколько дорожек. Например, для параллельной передачи 32 сообщений могут использоваться 32 дорожки. Из-за быстрого роста скоростей передачи данных таких периферийных устройств, как сетевые карты и графические адаптеры, стандарт PCIe обновляется каждые 3–5 лет. Например, 16 дорожек PCIe 2.0 предлагали скорость 64 Гбит/с. Обновление до PCIe 3.0 удваивает эту скорость, а обновление до PCIe 4.0 — удваивает еще раз.
Архитектура параллельной шины, подобная той, что используется в PCI, предполагает отправку каждого слова данных по нескольким проводникам. Например, в обычных шинах PCI одно 32-разрядное число отправляется по 32 параллельным проводникам. В отличие от этого в PCIe используется архитектура последовательной шины, и все биты сообщения отправляются по одному соединению, известному как дорожка (lane), что очень похоже на отправку сетевого пакета. Это существенно упрощает задачу, поскольку обеспечивать абсолютно одновременное прибытие всех 32 битов в пункт назначения уже не нужно. Но параллелизм все же используется, поскольку параллельно могут действовать сразу несколько дорожек. Например, для параллельной передачи 32 сообщений могут использоваться 32 дорожки. Из-за быстрого роста скоростей передачи данных таких периферийных устройств, как сетевые карты и графические адаптеры, стандарт PCIe обновляется каждые 3–5 лет. Например, 16 дорожек PCIe 2.0 предлагали скорость 64 Гбит/с. Обновление до PCIe 3.0 удваивает эту скорость, а обновление до PCIe 4.0 — удваивает еще раз.