Готовые презентации на тему:
- Образование
- Искусство и Фото
- Наши презентации
- Авто/мото
- Бизнес и предпринимательство
- Технологии
- Карьера
- Данные и аналитика
- Дизайн
- Устройства и комплектующие
- Экономика и Финансы
- Машиностроение
- Развлечения и Юмор
- Путешествия
- Eда
- Политика
- Юриспруденция
- Здоровье и Медицина
- Интернет
- Инвестиции
- Закон
- Стиль жизни
- Маркетинг
- Мобильные технологии
- Новости
- Недвижимость
- Рекрутинг
- Розничная торговля
- Таможня, ВЭД, Логистика
- Наука
- Услуги
- Программное обеспечение
- Спорт
- Музыка
- Шаблоны презентации
- Детские презентации
- Английский язык
- Астрономия
- Алгебра
- Биология
- География
- Геометрия
- История
- Литература
- Информатика
- Математика
- Обществознание
- Русский язык
- Физика
- Философия
- МХК
- ОБЖ
- Окружающий мир
- Педагогика
- Технология
- Химия
- Начальная школа
- Раскраски для детей
- Товароведение
- Менеджмент
- Страхование





























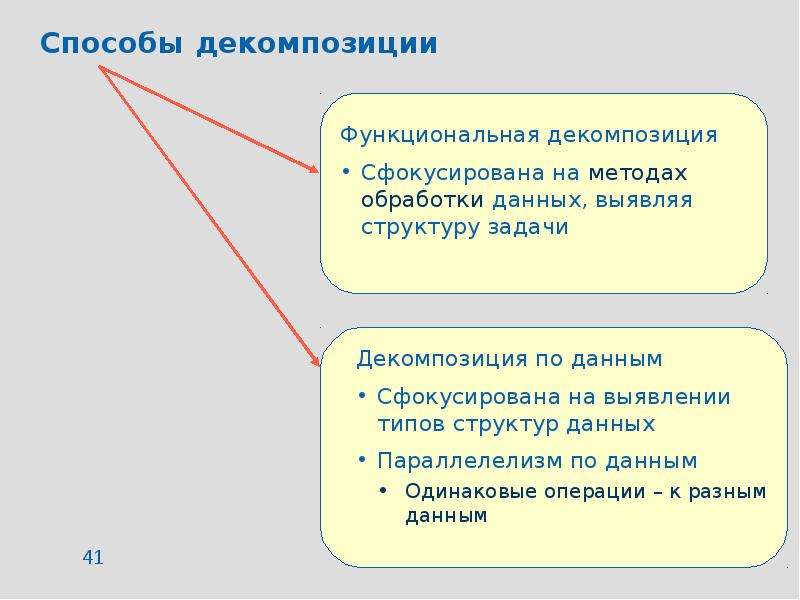


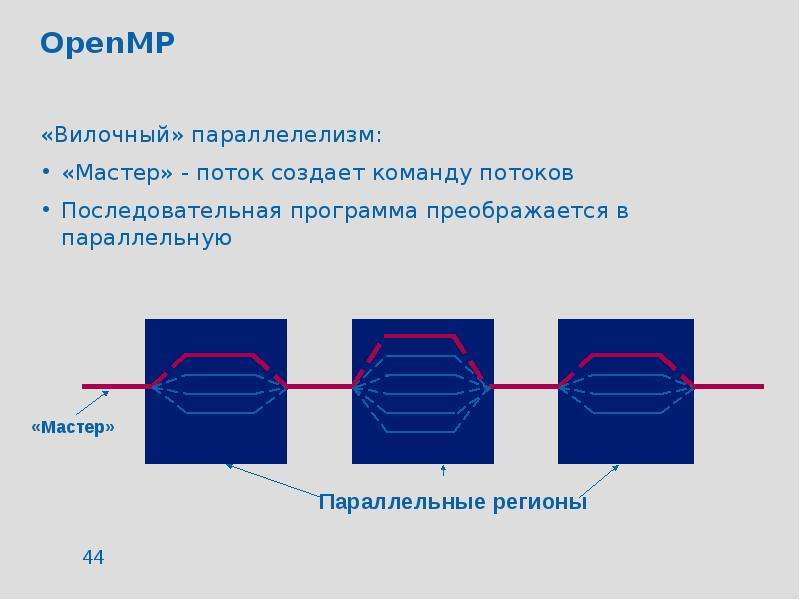
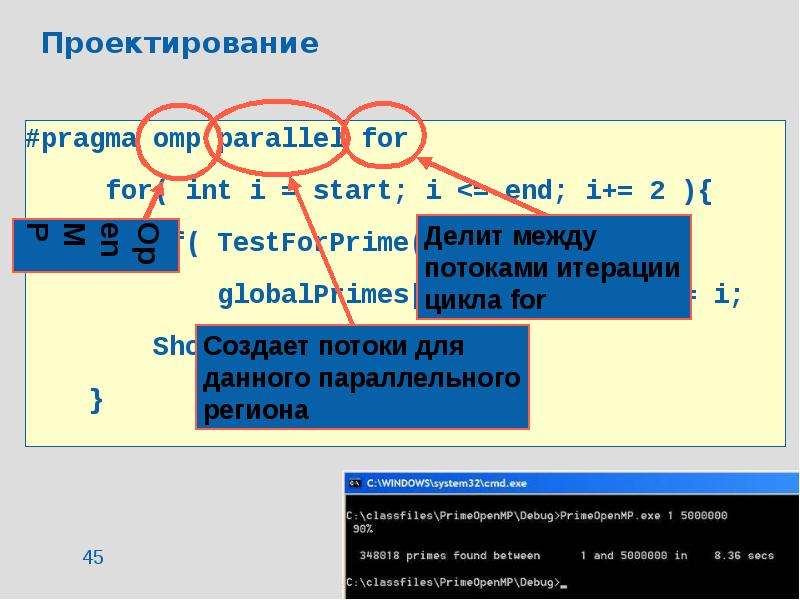


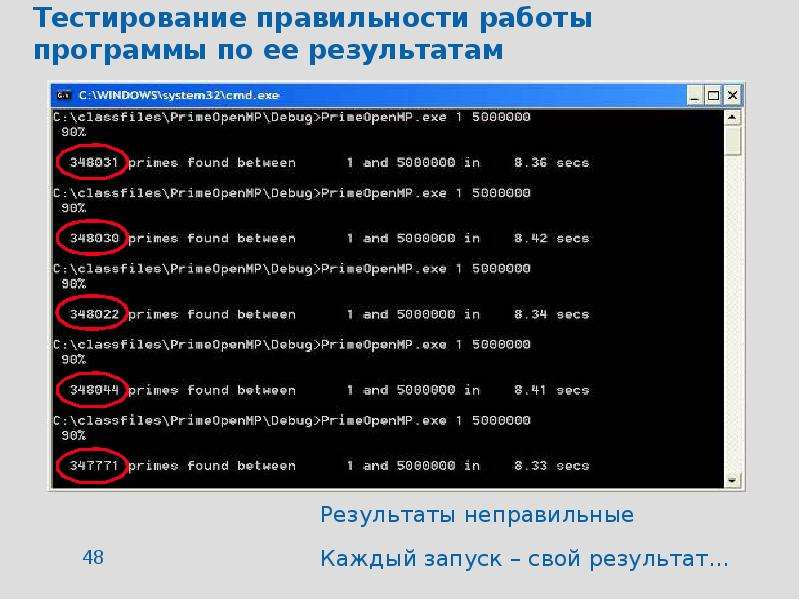






















![Чума́ (лат. pestis — зараза) — острое природно-очаговое инфекционное заболевание группы карантинных инфекций, протекающее с исключительно тяжёлым общим состоянием, лихорадкой, поражением лимфоузлов, лёгких и других внутренних органов, часто с развитием сепсиса. Заболевание характеризуется высокой летальностью и крайне высокой заразностью. В природных очагах источниками и резервуарами возбудителя инфекции являются грызуны — сурки, суслики и песчанки, мышевидные грызуны, крысы (серая и черная), реже домовые мыши, а также зайцеобразные, кошки и верблюды. Переносчики возбудителя инфекции — блохи различных видов[1]. Возбудителем является чумная палочка (лат. Yersinia pestis), открытая в 1894 году одновременно двумя учёными: французом Александром Йерсеном и японцем Китасато Сибасабуро. Инкубационный период длится от нескольких часов до 3—6 дней. Наиболее распространённые формы чумы — бубонная и лёгочная. Смертность при бубонной форме чумы достигала 95 %, при лёгочной — 98-99 %. В настоящее время при правильном лечении смертность составляет 5-10 %[2] Известные эпидемии чумы, унёсшие миллионы жизней, оставили глубокий след в истории всего человечества.](/documents/e910cf6e63d0bdd1792ee703cb31ce55/thumb.jpg)