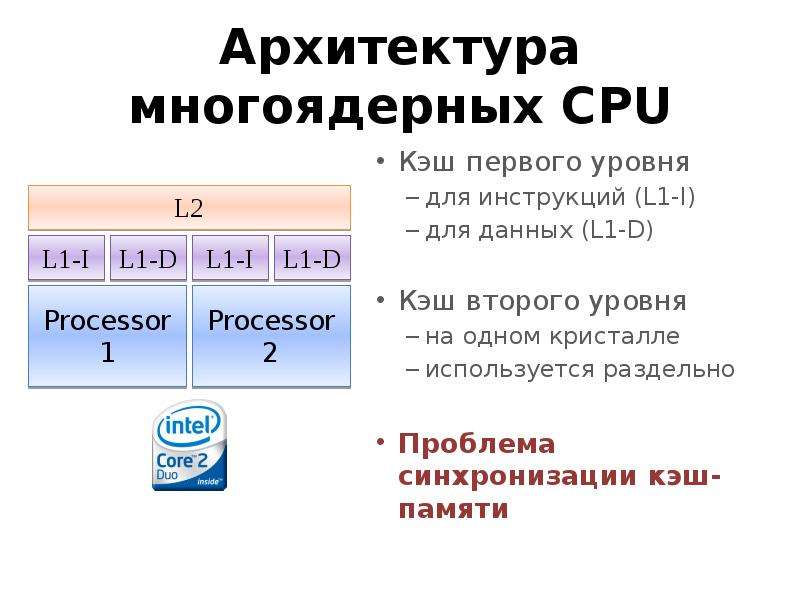
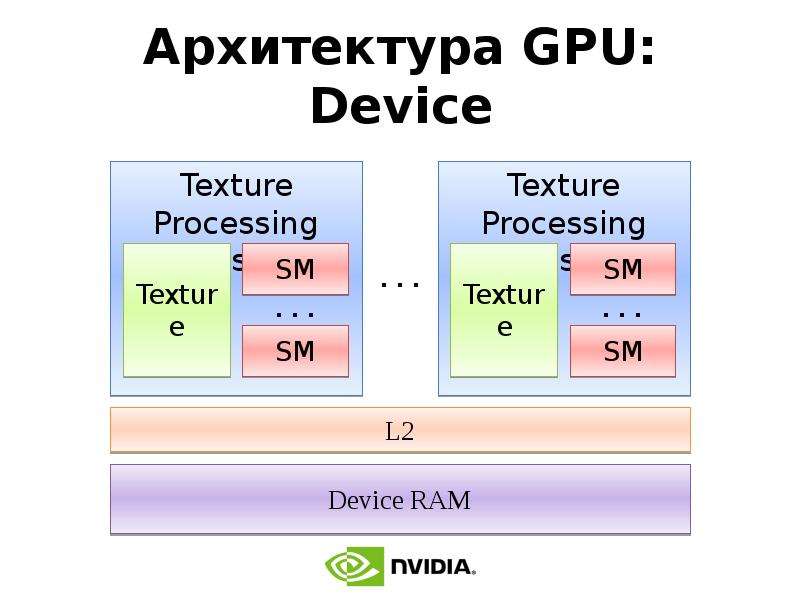
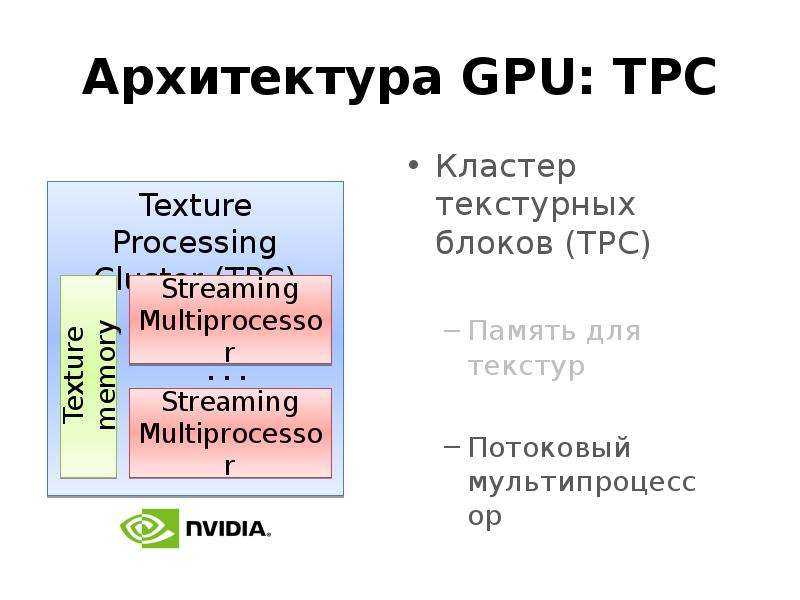
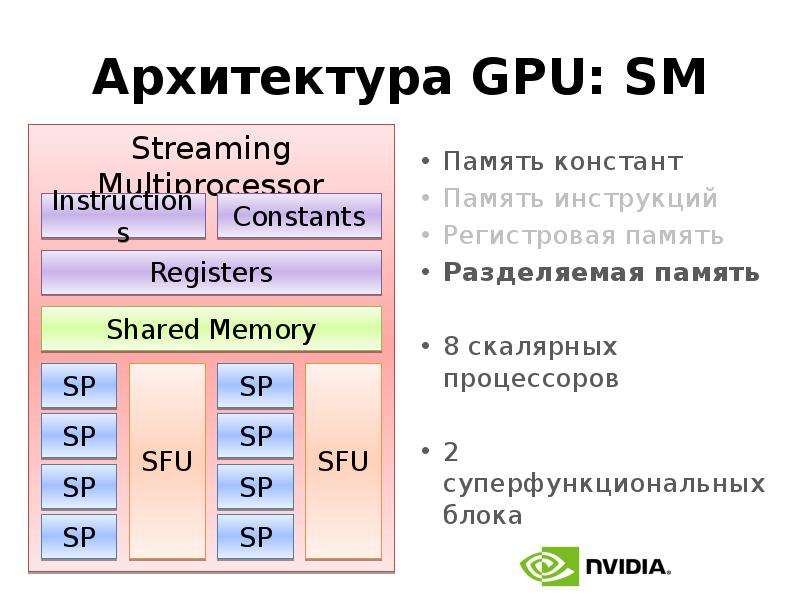
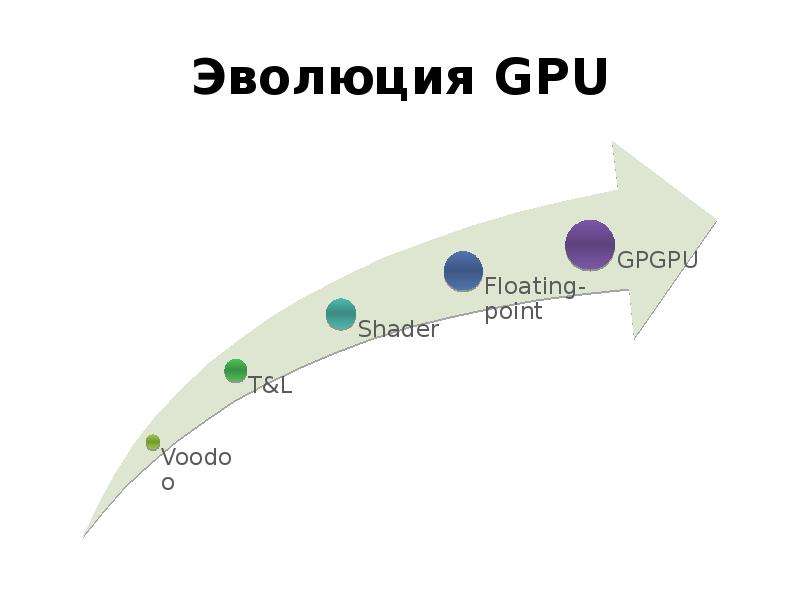
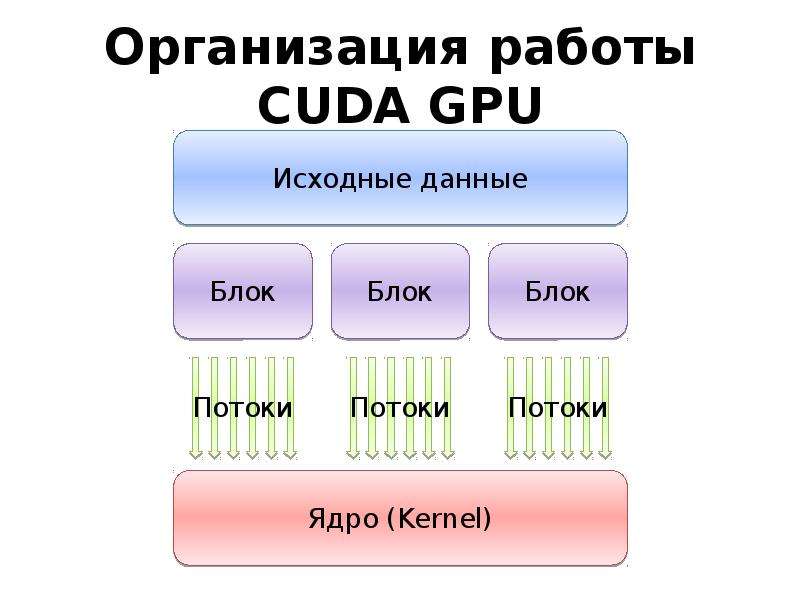
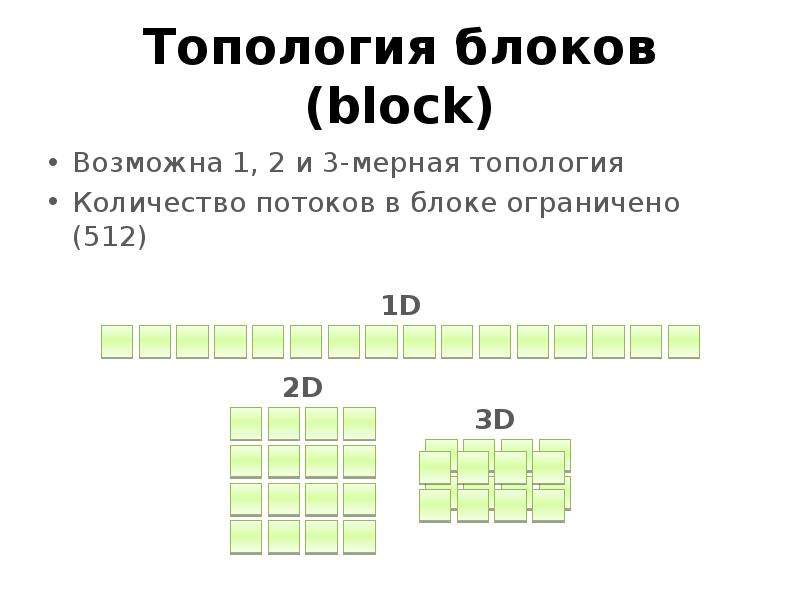
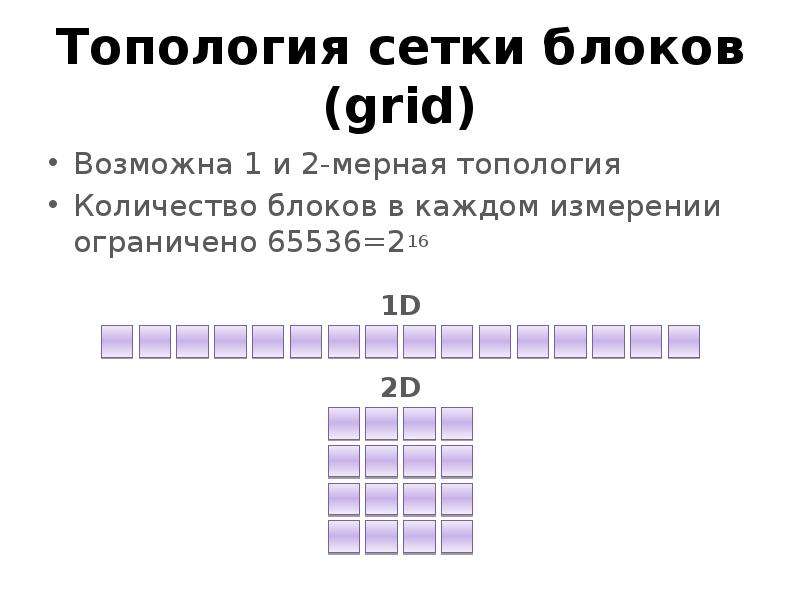
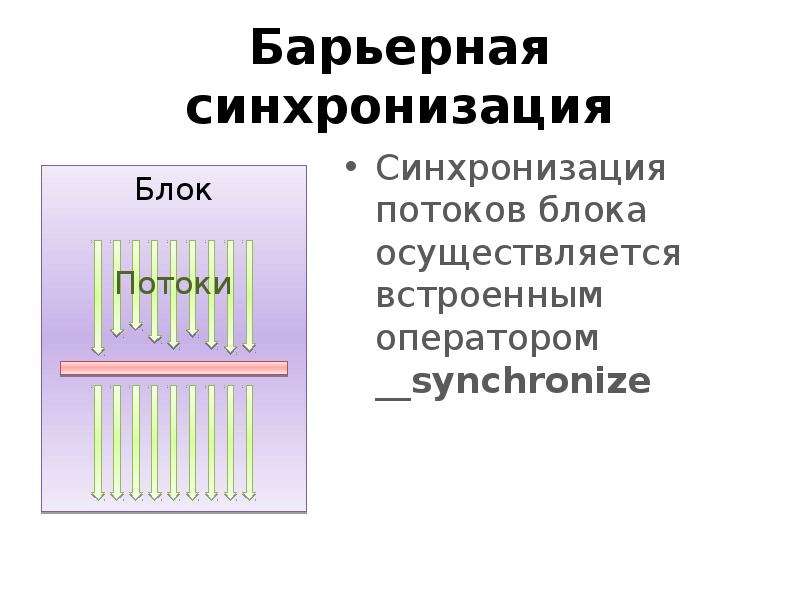
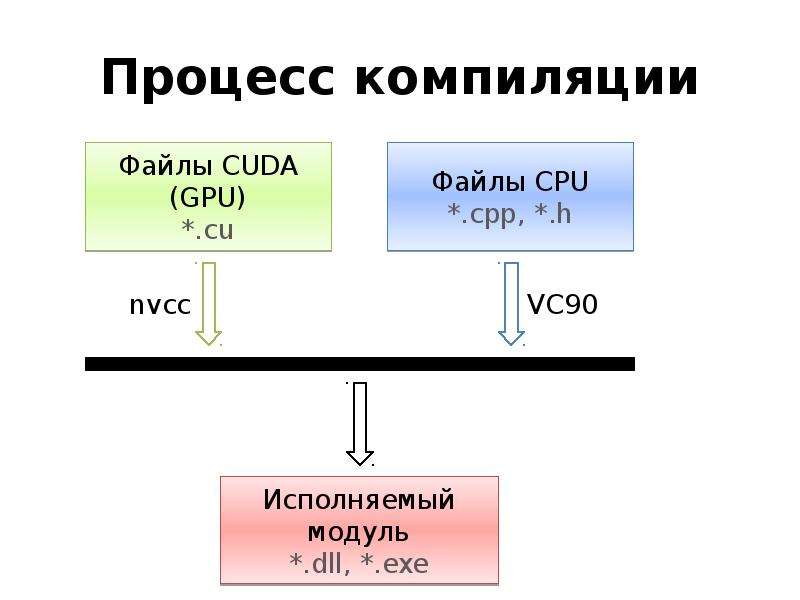
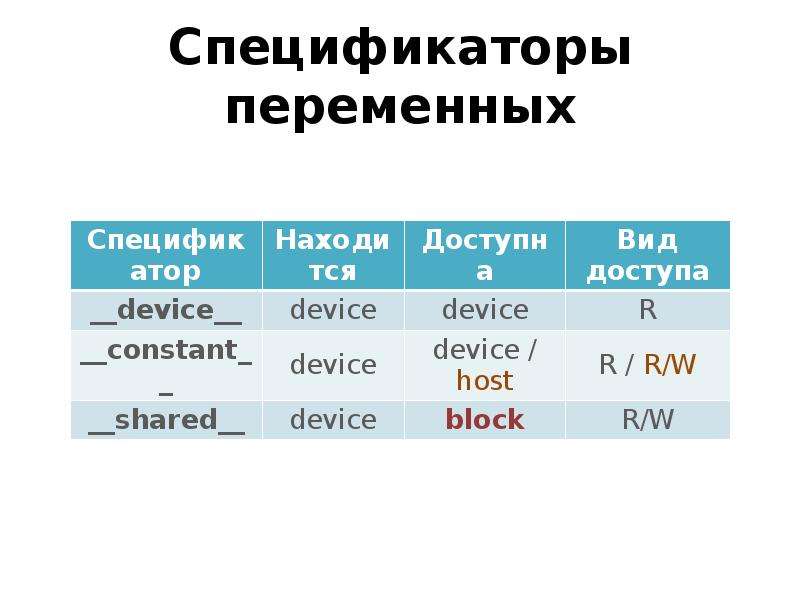
Готовые презентации на тему:
- Образование
- Искусство и Фото
- Наши презентации
- Авто/мото
- Бизнес и предпринимательство
- Технологии
- Карьера
- Данные и аналитика
- Дизайн
- Устройства и комплектующие
- Экономика и Финансы
- Машиностроение
- Развлечения и Юмор
- Путешествия
- Eда
- Политика
- Юриспруденция
- Здоровье и Медицина
- Интернет
- Инвестиции
- Закон
- Стиль жизни
- Маркетинг
- Мобильные технологии
- Новости
- Недвижимость
- Рекрутинг
- Розничная торговля
- Таможня, ВЭД, Логистика
- Наука
- Услуги
- Программное обеспечение
- Спорт
- Музыка
- Шаблоны презентации
- Детские презентации
- Английский язык
- Астрономия
- Алгебра
- Биология
- География
- Геометрия
- История
- Литература
- Информатика
- Математика
- Обществознание
- Русский язык
- Физика
- Философия
- МХК
- ОБЖ
- Окружающий мир
- Педагогика
- Технология
- Химия
- Начальная школа
- Раскраски для детей
- Товароведение
- Менеджмент
- Страхование