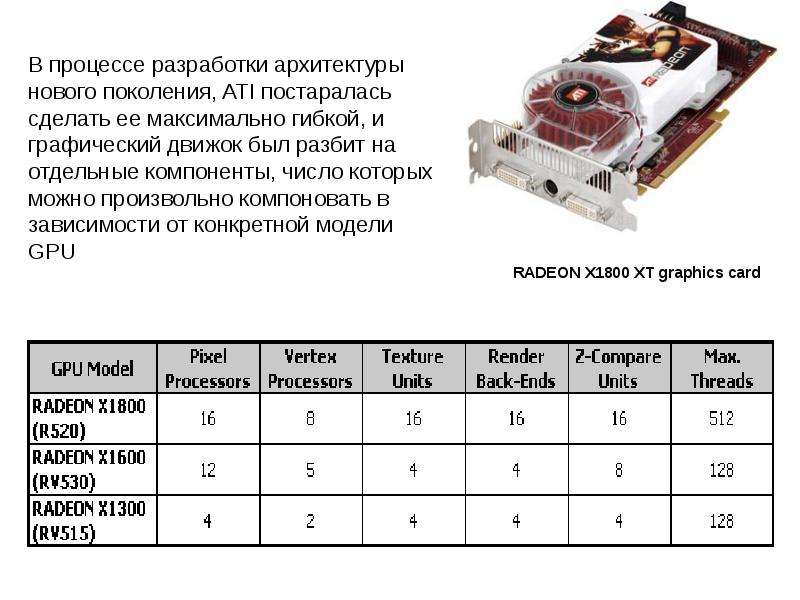
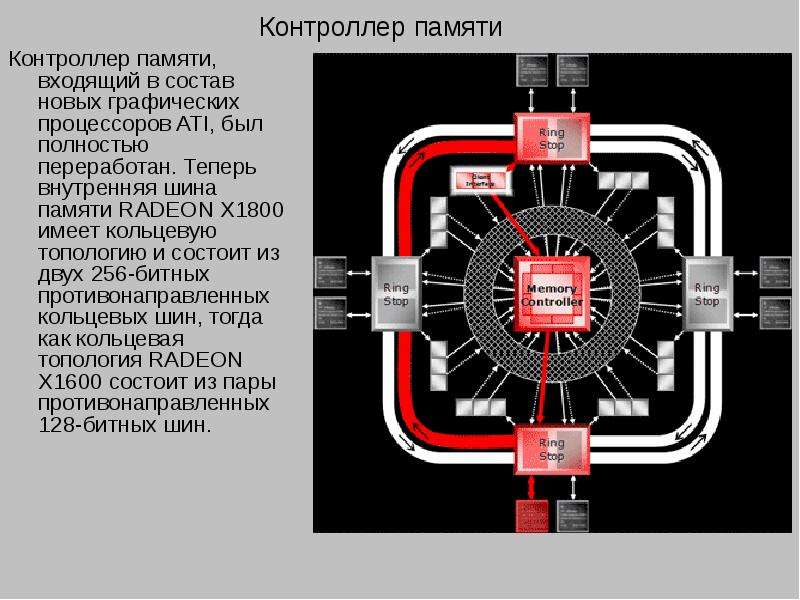
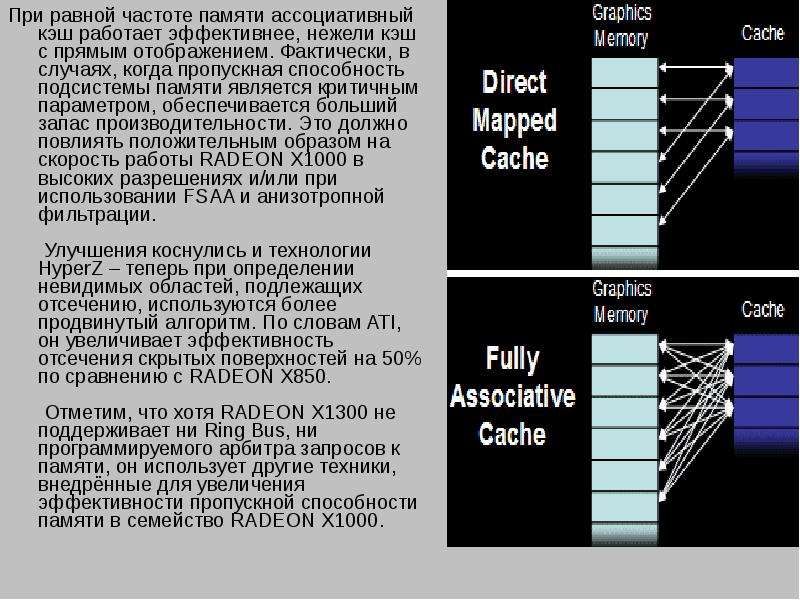
Описание слайда:
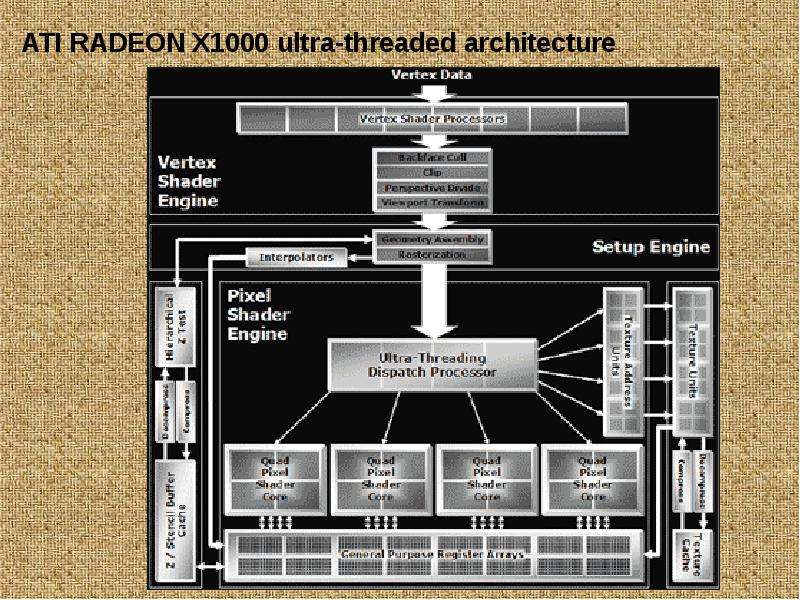
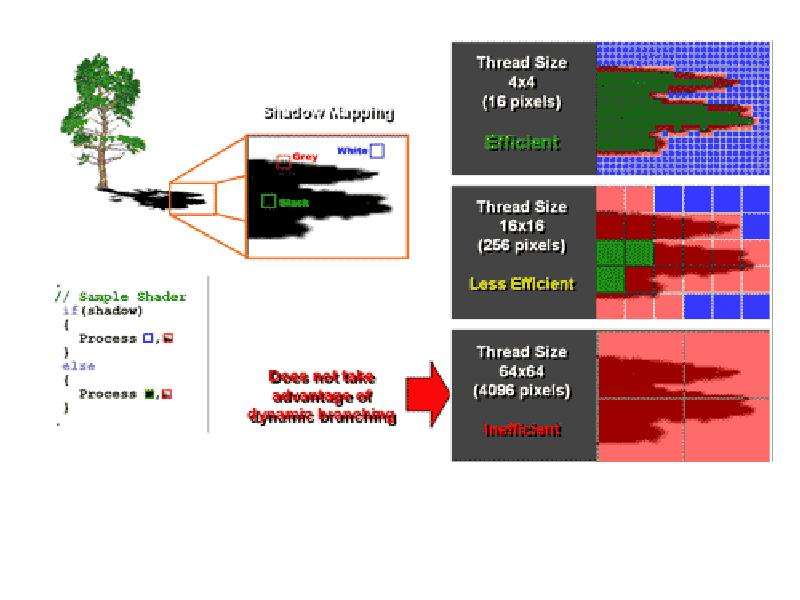
Ultra-Threading Dispatch Processor распознаёт случаи, когда какие-либо пиксельные процессоры внутри квадов простаивают и моментально назначают им на выполнение новые задачи. Однако, в случае, когда для продолжения выполнения шейдера требуются еще не полученные данные, то подобная нить приостанавливается арбитражным процессором до их получения, таким образом высвобождая арифметические ресурсы (Arithmetic Logic Unit, ALU) для других нитей и маскируя латентность, к примеру, выборки текстур, находящихся как в кеше, так и в памяти. Согласно ATI, подобная организация работы позволяет достигать 90% эффективности задействования пиксельных процессоров на любых шейдерах. Поскольку быстрое переключение между нитями требует сохранения промежуточных результатов каждой, ATI использует для этого специальные регистры - General Purpose Register Array - с высокоскоростным соединением с пиксельными процессорами, что мы уже видели в предыдущих графических процессорах. Пока непонятно, какое колиечество регистров имеется в RADEON X1800, X1600 и X1300 и насколько чувствительны новые чипы к сложностям пиксельных шейдеров. Согласно стандарту Shader Model 3.0, циклы, ветвления и подпрограммы поддерживаются новыми решениями ATI в полной мере, а применение flow control позволяет им исполнять шейдеры практически неограниченной длины. Все вычисления процессоры семейства RADEON X1000 выполняют в формате 128-bit FP, что практически исключает возможность накопления ошибок и, как следствие, ухудшение качества изображения. Количество одновременно выполняемых нитей кода было увеличено, а размер каждой, напротив, уменьшен до 4х4 пикселей, что позволило добиться большей эффективности при использовании динамического ветвлении, принцип которого хорошо иллюстрирует следующая диаграмма: Ultra-Threading Dispatch Processor распознаёт случаи, когда какие-либо пиксельные процессоры внутри квадов простаивают и моментально назначают им на выполнение новые задачи. Однако, в случае, когда для продолжения выполнения шейдера требуются еще не полученные данные, то подобная нить приостанавливается арбитражным процессором до их получения, таким образом высвобождая арифметические ресурсы (Arithmetic Logic Unit, ALU) для других нитей и маскируя латентность, к примеру, выборки текстур, находящихся как в кеше, так и в памяти. Согласно ATI, подобная организация работы позволяет достигать 90% эффективности задействования пиксельных процессоров на любых шейдерах. Поскольку быстрое переключение между нитями требует сохранения промежуточных результатов каждой, ATI использует для этого специальные регистры - General Purpose Register Array - с высокоскоростным соединением с пиксельными процессорами, что мы уже видели в предыдущих графических процессорах. Пока непонятно, какое колиечество регистров имеется в RADEON X1800, X1600 и X1300 и насколько чувствительны новые чипы к сложностям пиксельных шейдеров. Согласно стандарту Shader Model 3.0, циклы, ветвления и подпрограммы поддерживаются новыми решениями ATI в полной мере, а применение flow control позволяет им исполнять шейдеры практически неограниченной длины. Все вычисления процессоры семейства RADEON X1000 выполняют в формате 128-bit FP, что практически исключает возможность накопления ошибок и, как следствие, ухудшение качества изображения. Количество одновременно выполняемых нитей кода было увеличено, а размер каждой, напротив, уменьшен до 4х4 пикселей, что позволило добиться большей эффективности при использовании динамического ветвлении, принцип которого хорошо иллюстрирует следующая диаграмма: