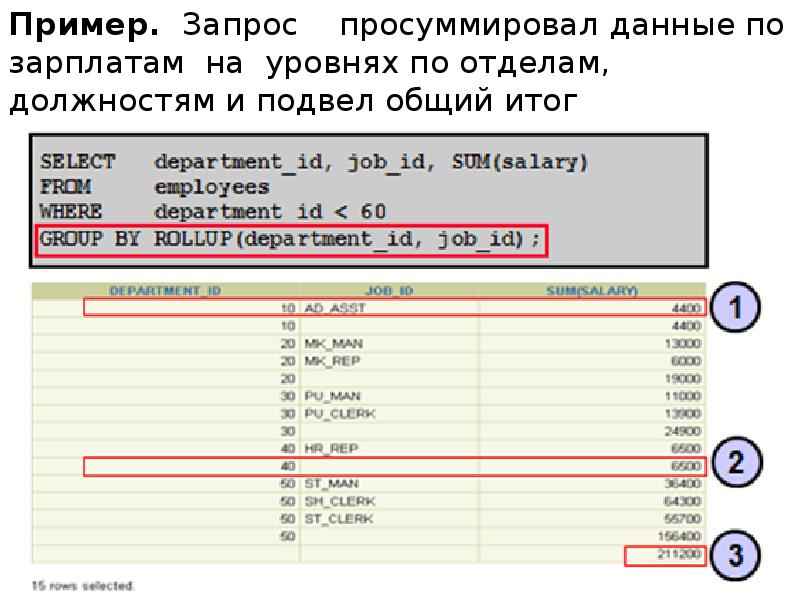
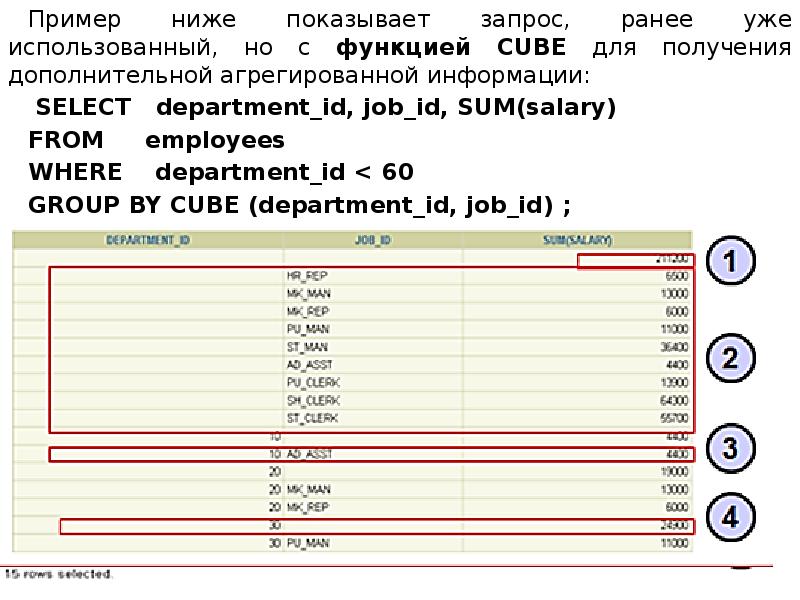
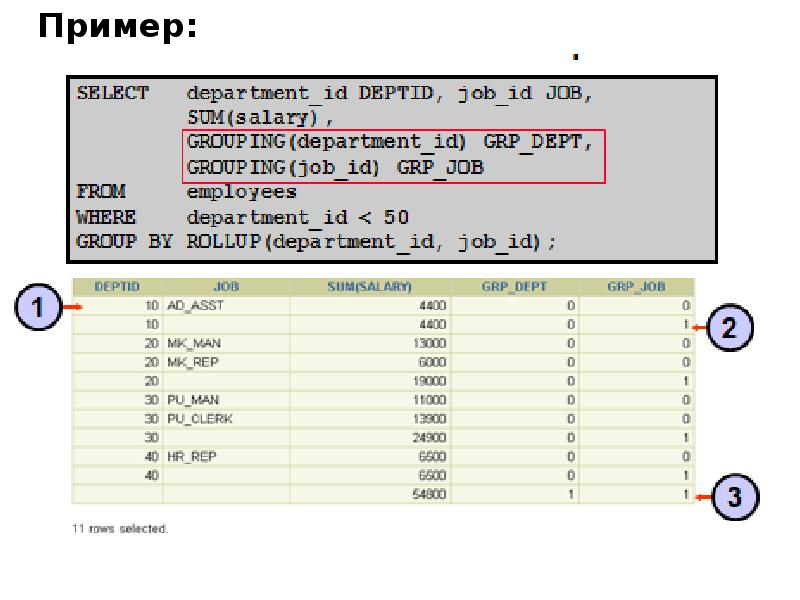
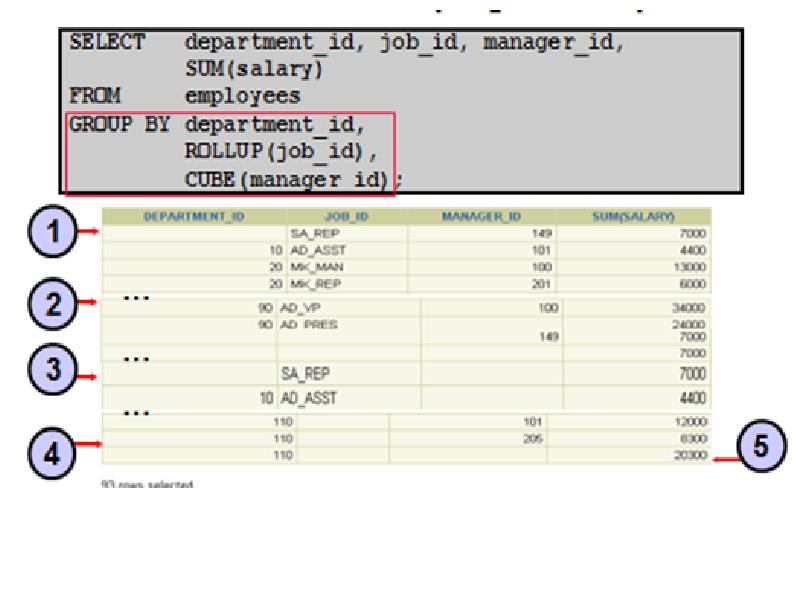
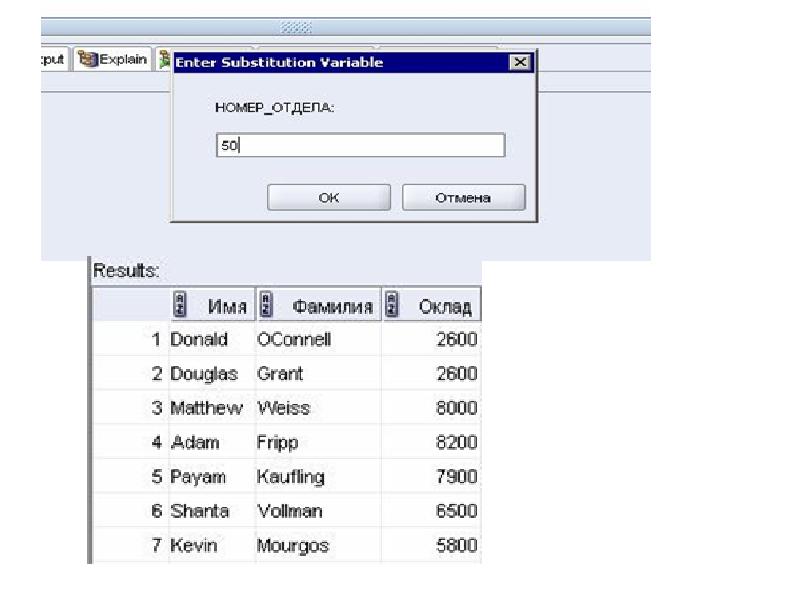
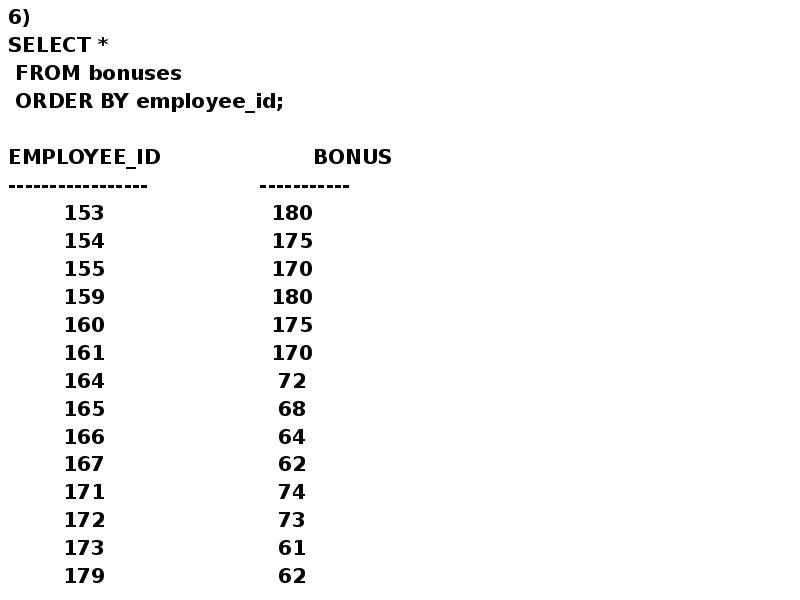
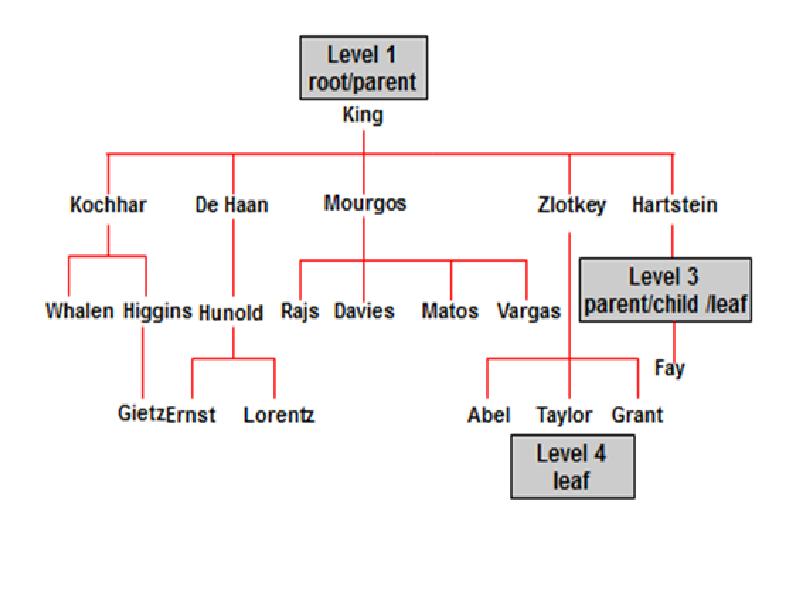
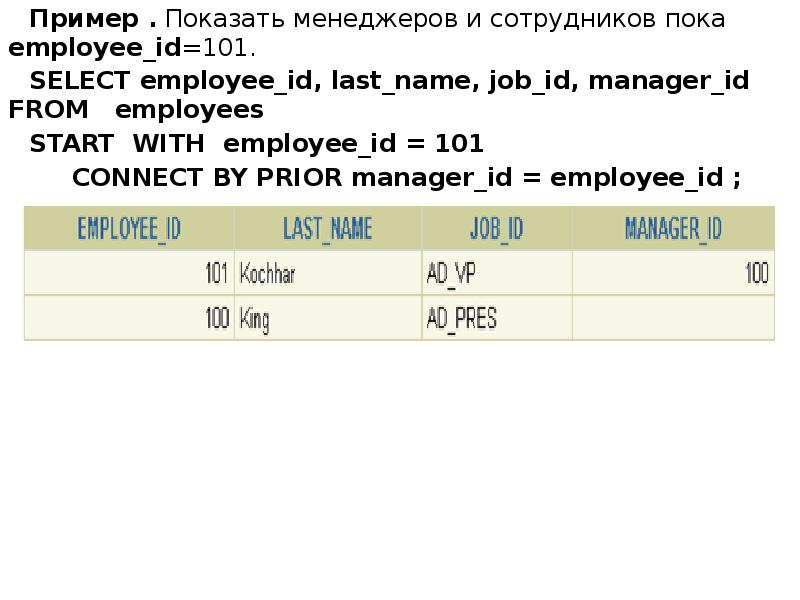
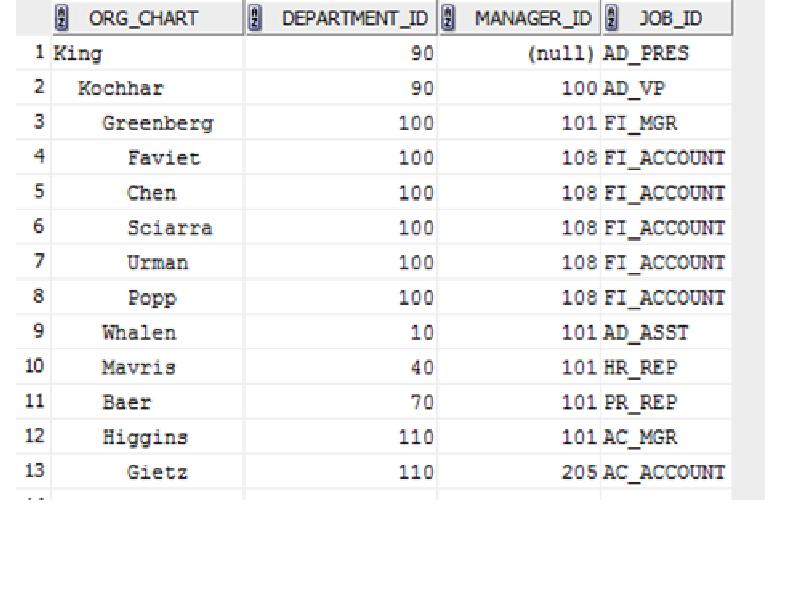
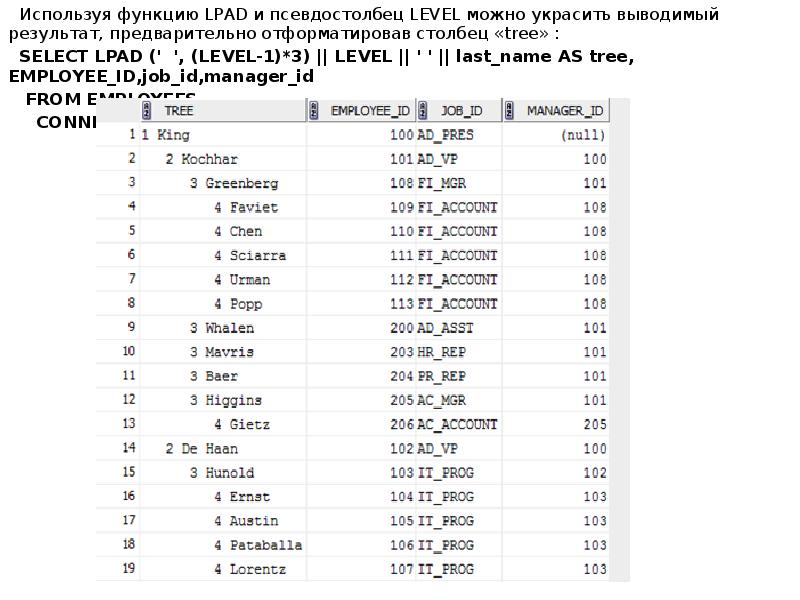
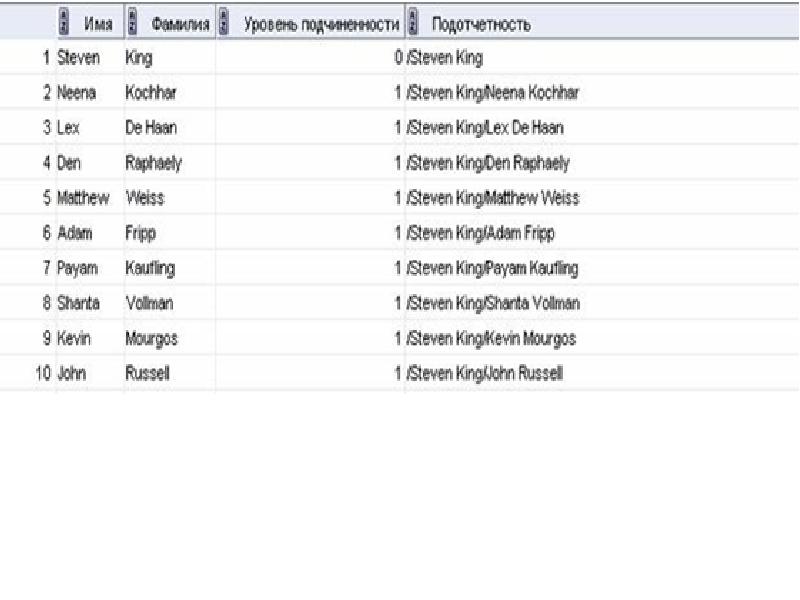
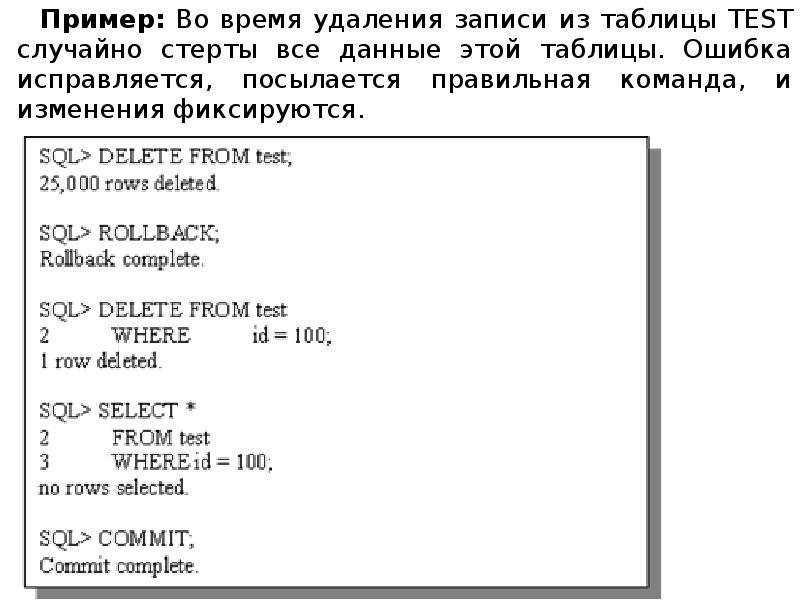
Описание слайда:
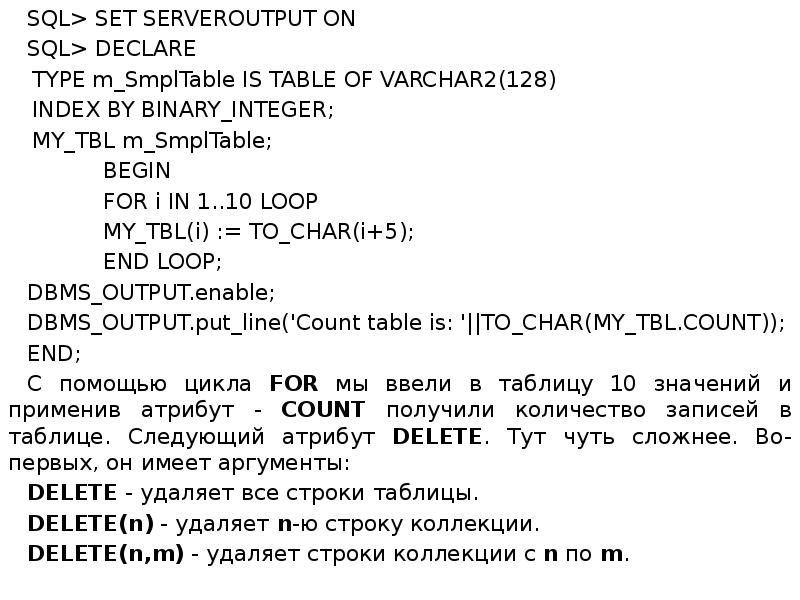
Составной тип TABLE! В своей сути это одномерный массив скалярного типа. Он не может содержать тип RECORD или другой тип TABLE. Но может быть объявлен от любого другого стандартного типа. TABLE может быть объявлен от атрибута %ROWTYPE! Вот где скрывается, по истине огромная мощь, этого типа данных! Тип TABLE, можно представить как одну из разновидностей коллекции. Хотя в более глубоком понимании это не совсем так. При первом рассмотрении он похож на массив языка C. Массив TABLE индексируется типом BINARY_INTEGER и может содержать, что-то вроде - 2,147,483,647 - 0 - + 2,147,483,647 как в положительную, так и в отрицательную часть. Начинать индексацию можно с 0 или 1 или любого другого числа. Если массив будет иметь разрывы, то это не окажет какой-либо дополнительной нагрузки на память. Так же следует помнить, что для каждого элемента, например, типа VARCHAR2 будет резервироваться столько памяти, сколько вы укажете, по этому определяйте размерность элементов по необходимости. Скажем не стоит объявлять VARCHAR2(255), если хотите хранить строки менее 100 символов! Составной тип TABLE! В своей сути это одномерный массив скалярного типа. Он не может содержать тип RECORD или другой тип TABLE. Но может быть объявлен от любого другого стандартного типа. TABLE может быть объявлен от атрибута %ROWTYPE! Вот где скрывается, по истине огромная мощь, этого типа данных! Тип TABLE, можно представить как одну из разновидностей коллекции. Хотя в более глубоком понимании это не совсем так. При первом рассмотрении он похож на массив языка C. Массив TABLE индексируется типом BINARY_INTEGER и может содержать, что-то вроде - 2,147,483,647 - 0 - + 2,147,483,647 как в положительную, так и в отрицательную часть. Начинать индексацию можно с 0 или 1 или любого другого числа. Если массив будет иметь разрывы, то это не окажет какой-либо дополнительной нагрузки на память. Так же следует помнить, что для каждого элемента, например, типа VARCHAR2 будет резервироваться столько памяти, сколько вы укажете, по этому определяйте размерность элементов по необходимости. Скажем не стоит объявлять VARCHAR2(255), если хотите хранить строки менее 100 символов!