Описание слайда:
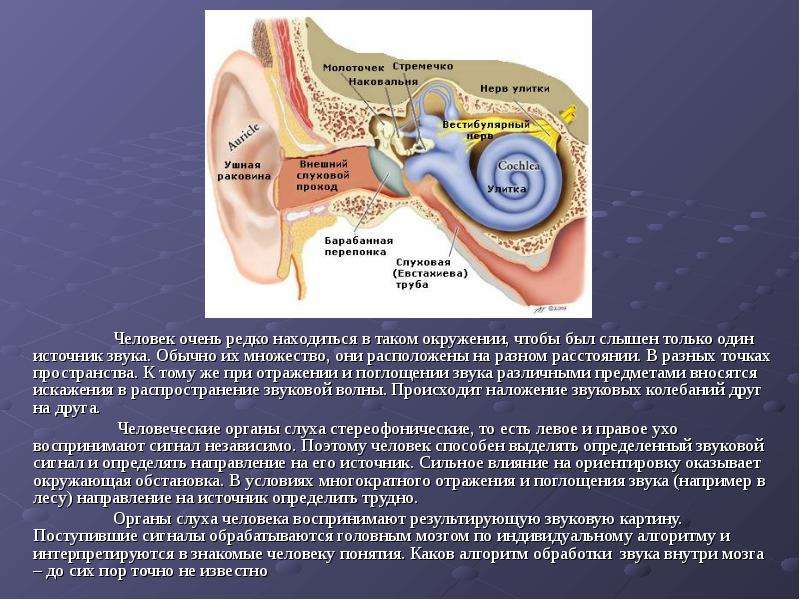
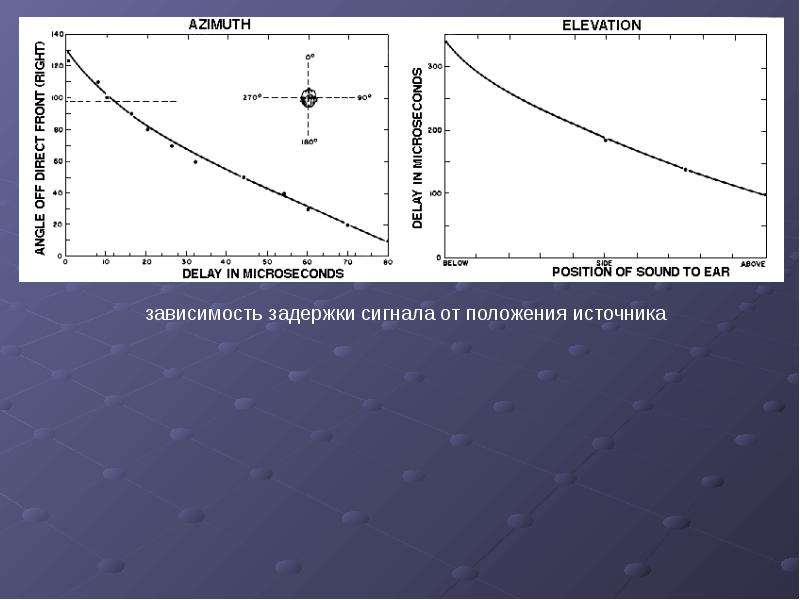
Пространственное звучание Пространственное звучание Человек слышит двумя ушами и поэтому способен различать направление прихода звуковых сигналов. Эту способность слуховой системы человека называют би-науральным эффектом. Механизм распознавания направления прихода звуков сложен, и надо сказать, что в его изучении и способах применения еще не поставлена точка. Уши человека расположены на расстоянии друг от друга (по ширине головы). Скорость распространения звуковой волны невелика. Сигнал, приходящий от источника звука, находящегося напротив слушателя, приходит в оба уха одновременно, и мозг интерпретирует это как расположение источника сигнала либо позади, либо спереди, но не сбоку. Если же сигнал приходит от источника, смещенного относительно центра головы, то звук приходит в одно ухо раньше, чем во второе, что позволяет мозгу интерпретировать это как приход сигнала слева или справа и даже приблизительно определить угол прихода. Численно разница во времени прихода сигнала в левое и правое ухо, составляющая от 0 до 1 мс, смещает мнимый источник звука в сторону того уха, которое воспринимает сигнал раньше. Такой способ определения направления прихода звука используется мозгом в полосе частот от 300 Гц до 1 кГц. Направление прихода звука для частот выше 1 кГц определяется мозгом человека путем анализа громкости звука. Дело в том, что звуковые волны с частотой выше 1 кГц быстро затухают в воздушном пространстве. Поэтому интенсивность звуковых волн, доходящих до левого и правого ушей слушателя, отличаются, что позволяет мозгу определять направление прихода сигнала по разнице амплитуд. Если звук в одном ухе слышен лучше, чем в другом, следовательно, источник звука находится со стороны того уха, в котором он слышен лучше. Подспорьем в определении направления прихода звука является способность человека повернуть голову в сторону кажущегося источника звука, чтобы проверить верность определения. Способность мозга определять направление прихода звука по разнице во времени прихода сигнала в левое и правое ухо, а также путем анализа громкости сигнала используется в стереофонии. Имея всего два источника звука, можно создать у слушателя ощущение наличия мнимого источника зву ка между двумя физическими. Причем этот мнимый источник можно «расположить» в любой точке на линии, соединяющей два физических источника. Для этого нужно воспроизвести одну аудиозапись (например, со звуком рояля) через оба физических источника, но сделать это с некоторой временной задержкой в одном из них и соответствующей разницей в громкости. Грамотно используя описанный эффект, можно при помощи двухканальной аудиозаписи донести до слушателя почти такую картину звучания, какую он ощутил бы сам, лично присутствуя, например, на каком-нибудь концерте. Такую двухканальную запись называют стереофонической. Одноканальная же запись называется монофонической. На самом деле для качественного донесения до слушателя реалистичного пространственного звучания обычной стереофонической записи не всегда достаточно. Основная причина этого кроется в том, что стереосигнал, приходящий к слушателю от двух физических источников звука, определяет расположение мнимых источников лишь в той плоскости, в которой расположены реальные физические источники звука. Естественно, «окружить слушателя звуком» при этом не удается. По той же причине заблуждением является и мысль о том, что объемное звучание обеспечивается квадрофониче-ской (четырехканальной) системой (два источника перед слушателем и два позади него). В целом путем выполнения многоканальной записи нам удается лишь донести до слушателя тот звук, каким он был «услышан» расставленной нами звуковоспринимающей аппаратурой (микрофонами). Для воссоздания же более или менее реалистичного, действительно объемного звучания прибегают к принципиально другим подходам, в основе которых лежат более сложные приемы, моделирующие особенности слуховой системы человека, а также физические особенности и эффекты передачи звуковых сигналов в пространстве.