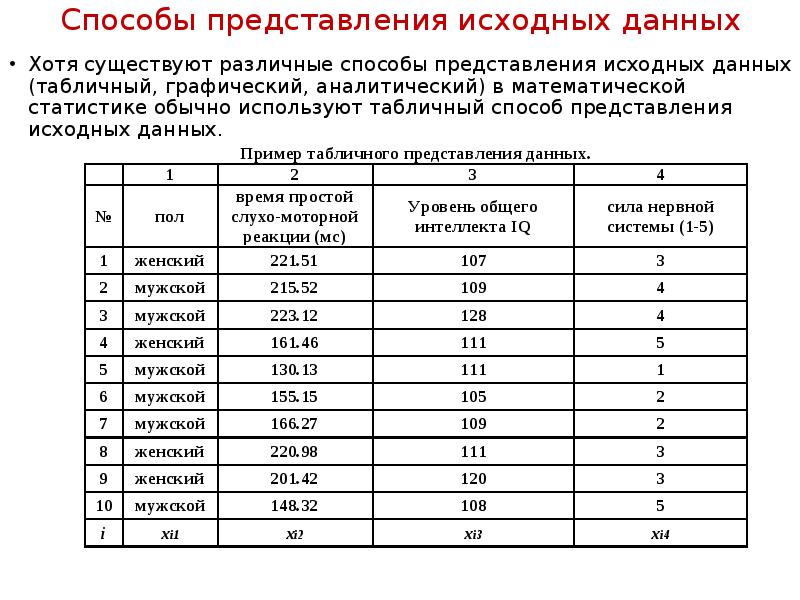
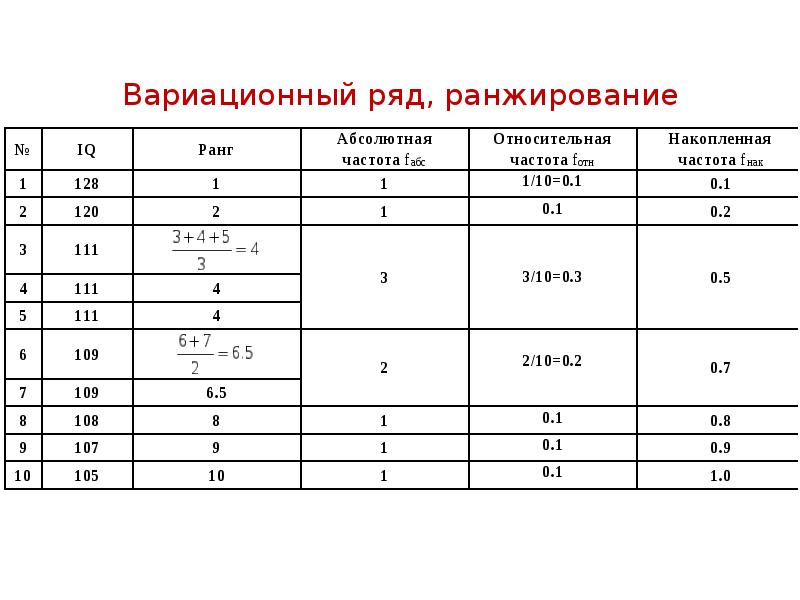
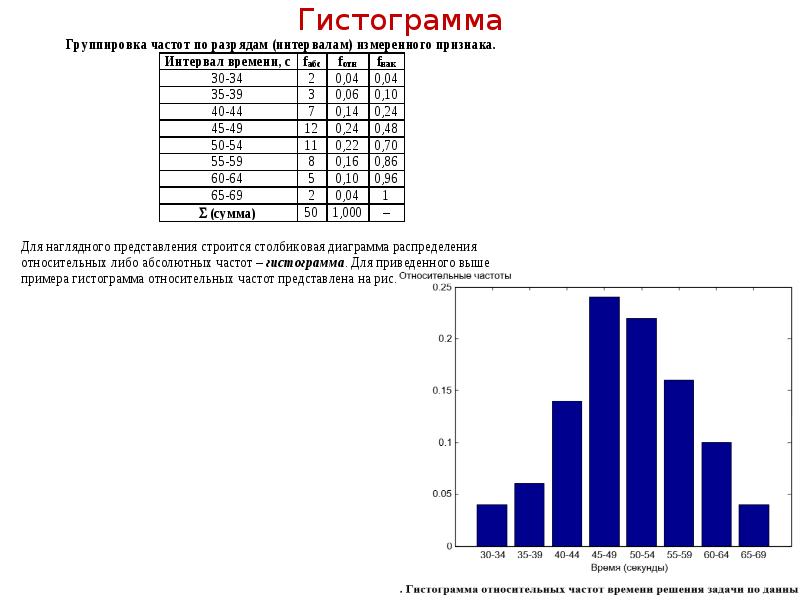
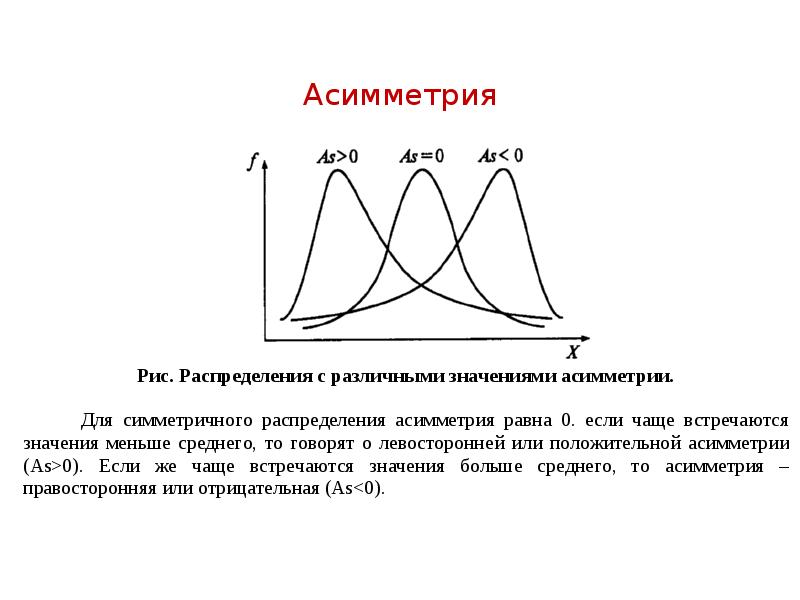
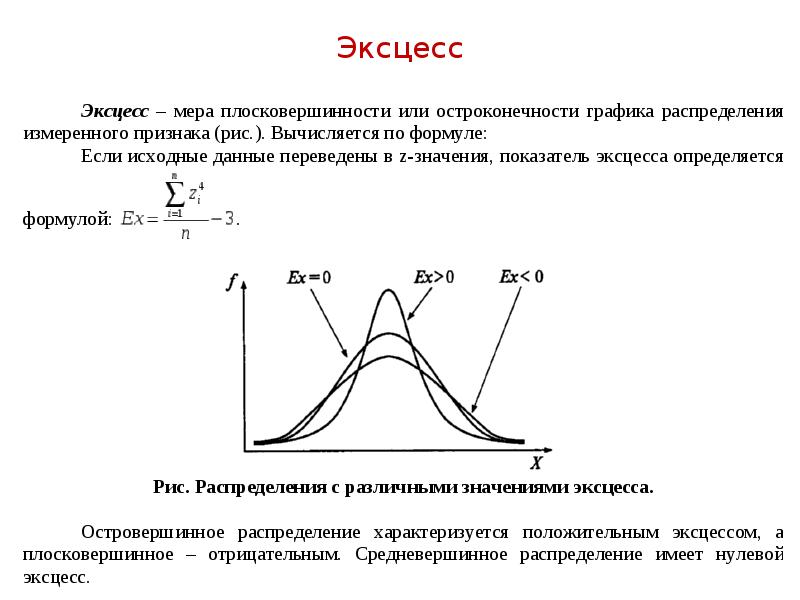
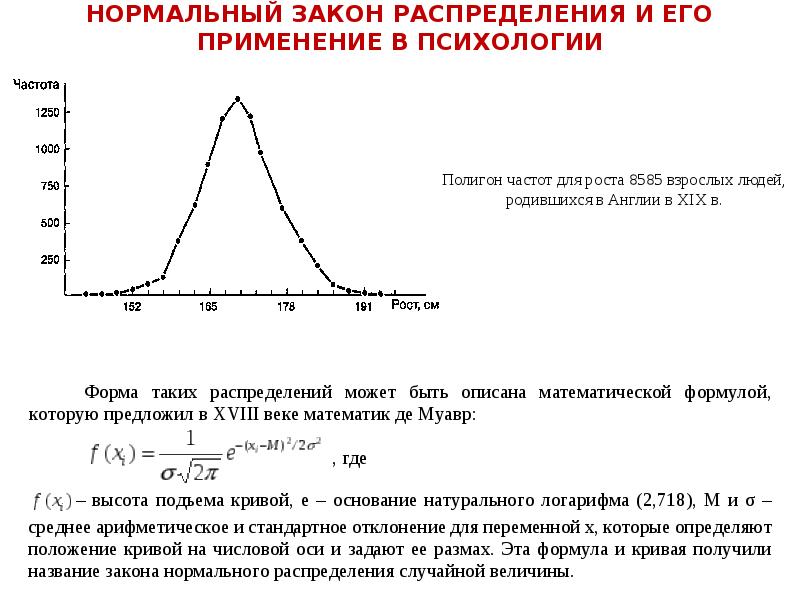
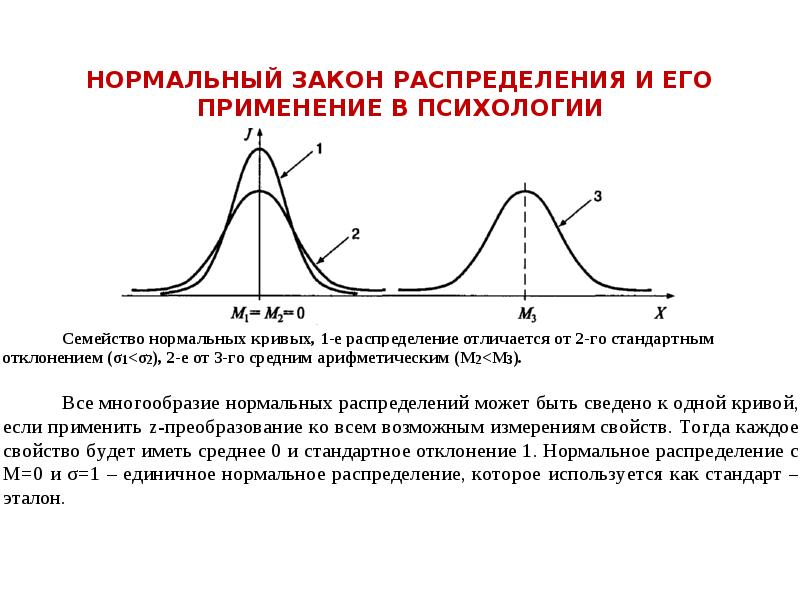
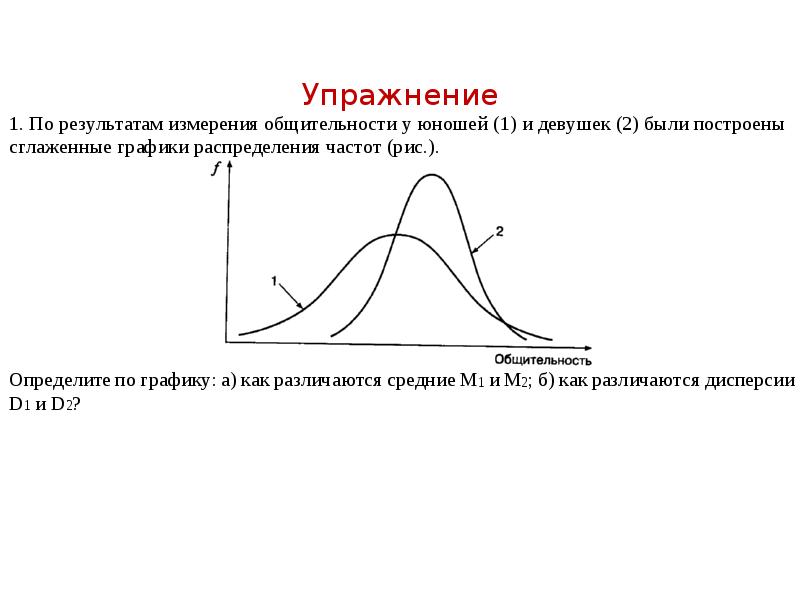
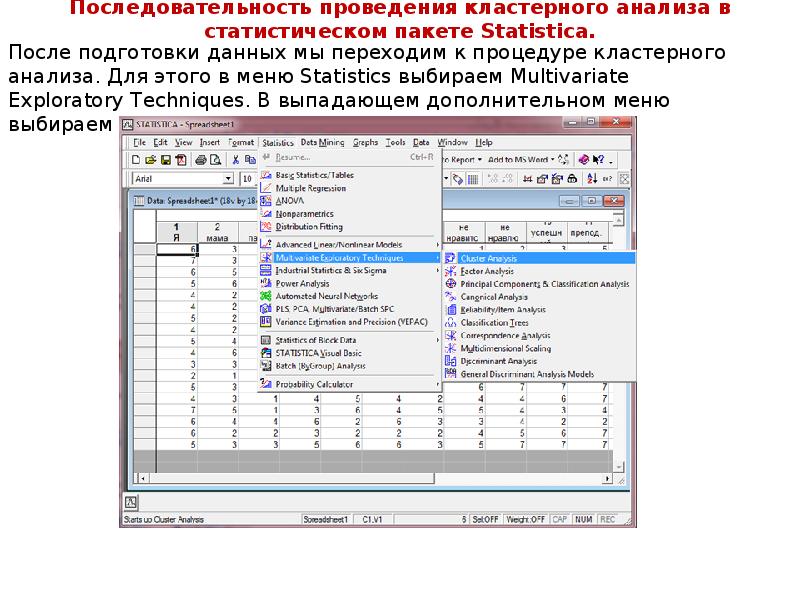
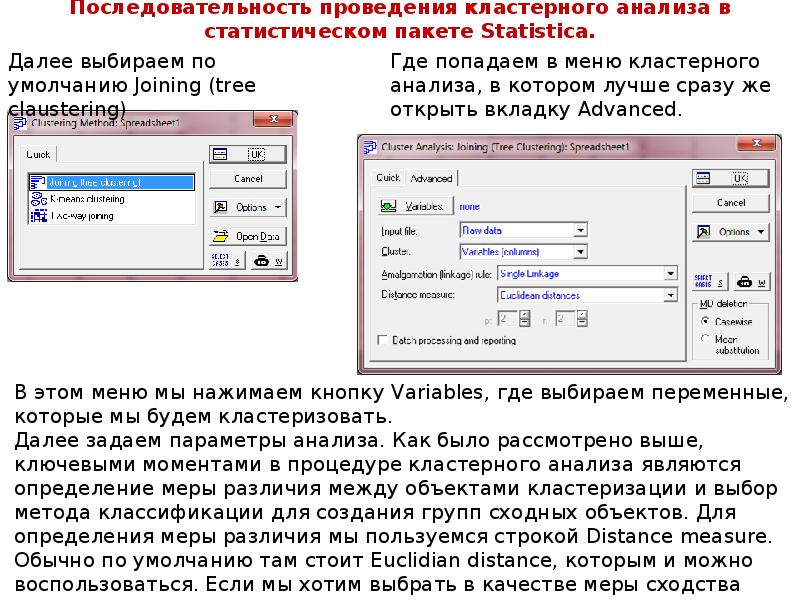
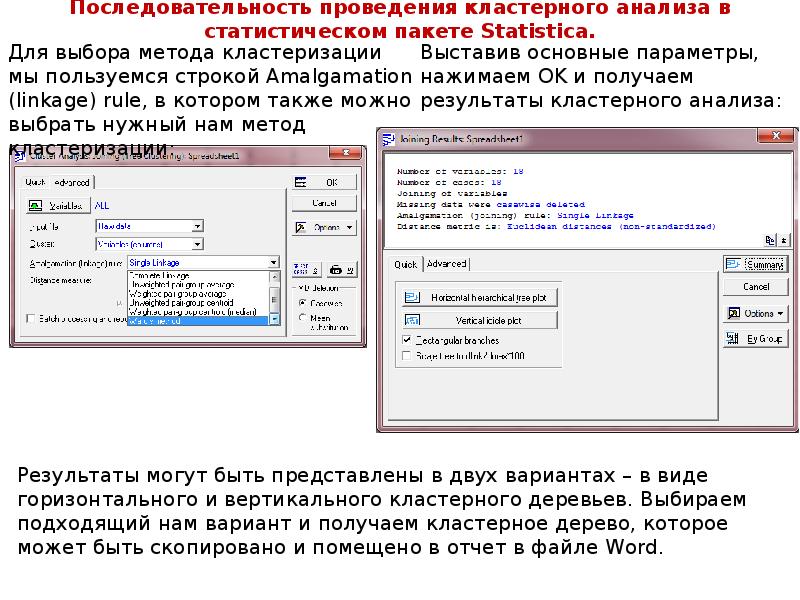
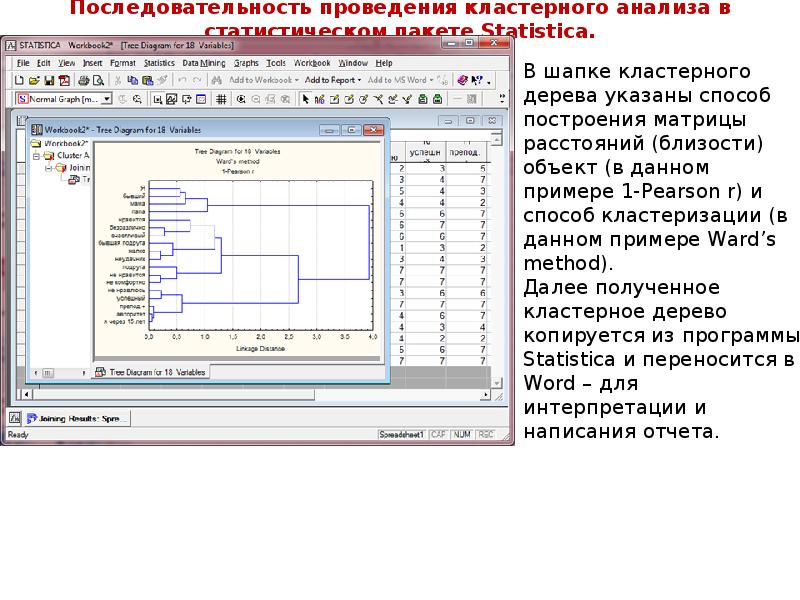
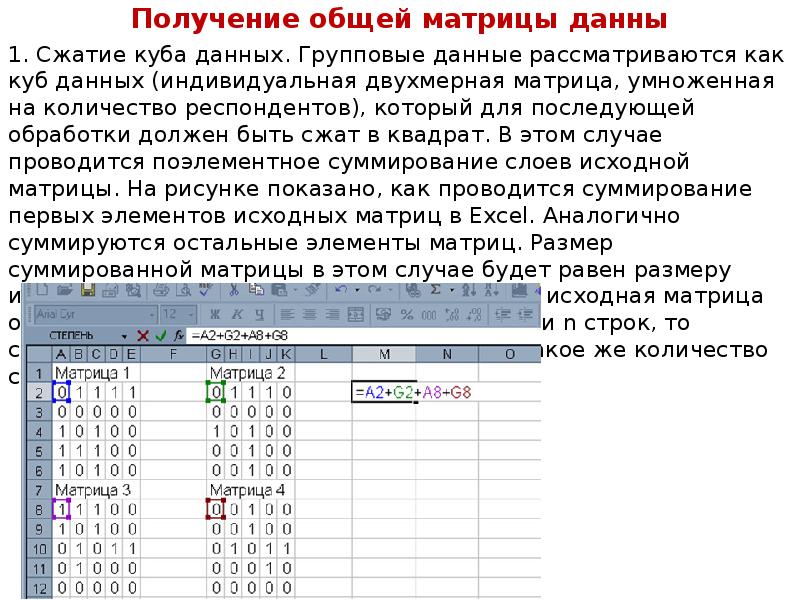
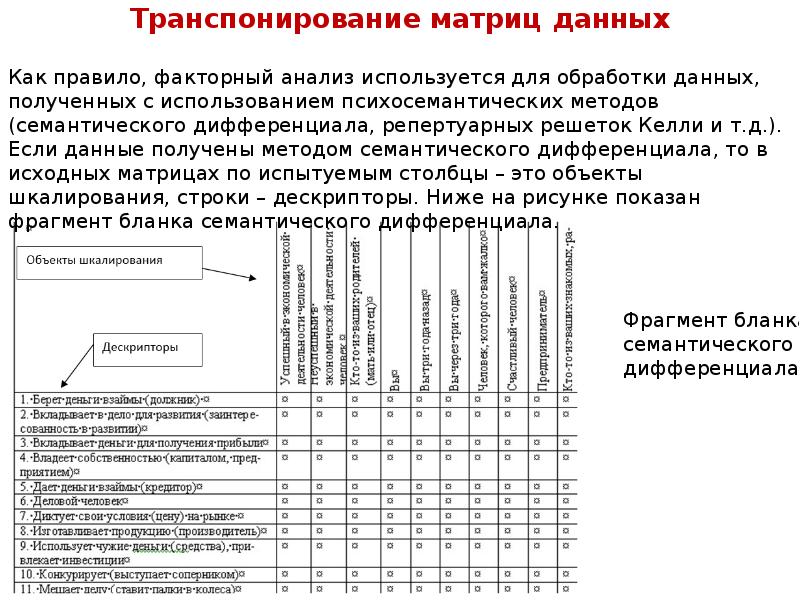
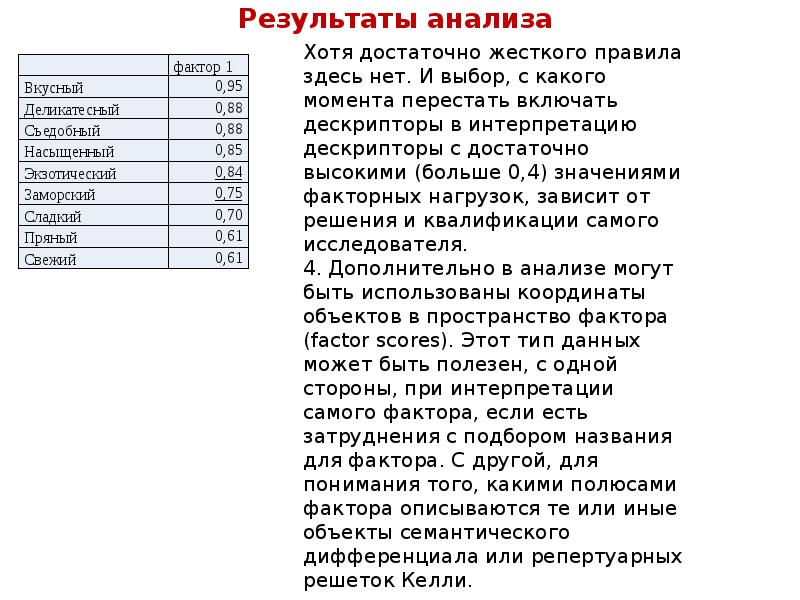
Описание слайда:
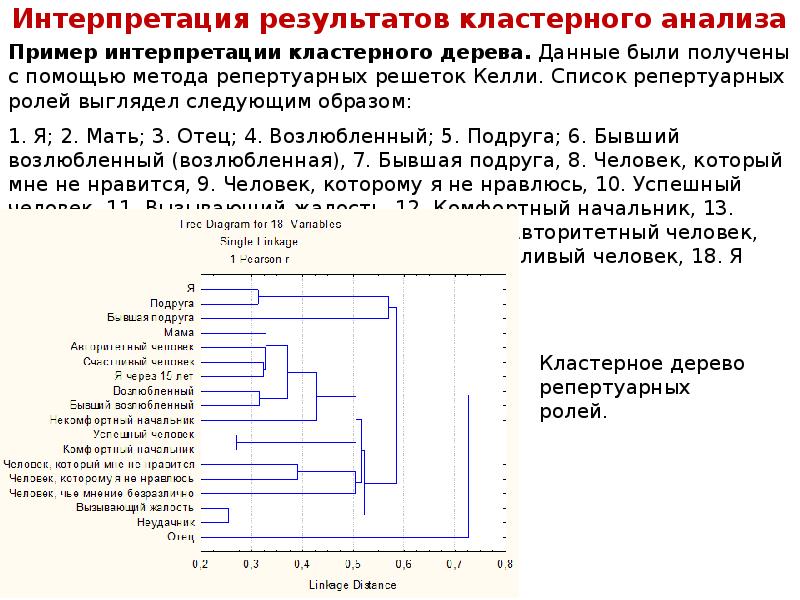
Интерпретация результатов кластерного анализа Следующий кластер объединяет роли «Успешный человек» и «Комфортный начальник». Можно предположить, что в представлении испытуемой успешный человек – это человек, реализовавшийся, в первую очередь, в сфере работы и как организатор, т.е. обладающий теми же качествами, что и начальник, под руководством которого комфортно работать. Четвертый кластер составляют «Человек, который мне не нравится» и «Человек, которому не нравлюсь я». Их объединение говорит об однозначной негативной оценке обоих и, возможно, представляет собой такой обобщенный образ «плохого» человека, характеризуемый оценками, близкими скорее к контрасту, нежели к конструкту. Последний кластер образуют «Вызывающий жалость» и «Неудачник», которые имеют самое сильное сходство среди всех ролей. Этот кластер автономен по отношению к другим, значит, испытуемая не ассоциирует ни себя, ни свое окружение с негативными качествами, проявляющимися в этих ролях. В целом, стоит обратить внимание на то, что роль «Я», описывающая испытуемую в актуальный момент, и роль «Я через 15 лет» находятся в разных кластерах и имеют слабую связь. Это может говорить о том, что разрыв между Я-реальным и Я-идеальным достаточно большой, что может являться следствием неадекватной самооценки, поэтому испытуемая может не представлять реальных способов продвижения к Я-идеальному, как, собственно, и к образу «Счастливого человека», также находящегося во втором кластере. Кроме того, свое будущее испытуемая ассоциирует скорее с семьей, чем с работой, т.к. обе роли, описывающие руководителя («Комфортный начальник», «Некомфортный начальник») находятся не в одном кластере с ролью «Я через 15 лет». Однако существует небольшая связь второго кластера с ролью «Некомфортного начальника». Это может говорить о том, что испытуемая не видит свое будущее на организаторском поприще, т.к. ассоциирует образ «Я через 15 лет» с «Некомфортным начальником». Однако, эта связь не дает достаточных оснований делать такой вывод и может быть объяснена схожими оценками этих двух ролей лишь по тем конструктам, которые не значимы в профессиональной деятельности.